

Understanding Decentralized Shared Sequencer for Scaling ETH

Good morning to all the Slytherins in the building and a happy new month. "Wgmi" this month. Yes, the topic for today is the Decentralized Shared Sequencer. As usual, it will be concise and easily understandable.
Scaling ETH is not an easy task, and Rollup teams have dedicated their efforts to achieve this. Earlier, it was thought that Monolithic chains were the key to scaling, but we were wrong. Modularity is the way and the only approach to scaling.
Decentralized Shared Sequencers is a modular approach that will help Rollups scale ETH.
Now let’s get to it
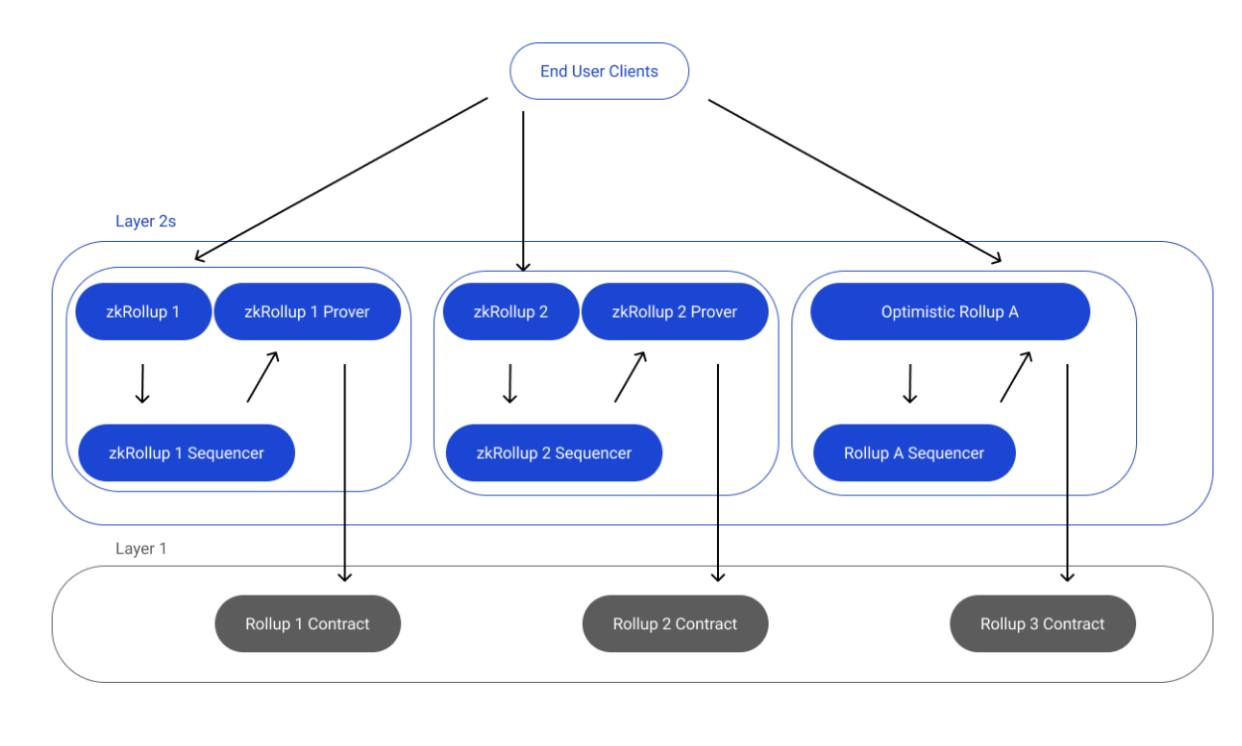
A decentralized Shared Sequencer is simply a sequencer layer shared across multiple rollups. At the moment every rollup has a Centralized sequencer layer. A Decentralized Shared Sequencer is decentralized because any rollup can opt into operating the sequencer. Hence, adding maximum security because of huge staked value and other benefits which will be discussed below
Current State of Rollup stack
The current Rollup stack is made up of these components:
Client software
Rollup VM
Mempool
Sequencer
Prover (Zero-Knowledge Rollups)
Rollup contract on ETH
1. Users create transactions with the client software (wallet)
2. These transactions are sent to the rollup and then queued in the mempool (The mempool is a storage area where unconfirmed transactions are temporarily held until they can be processed)
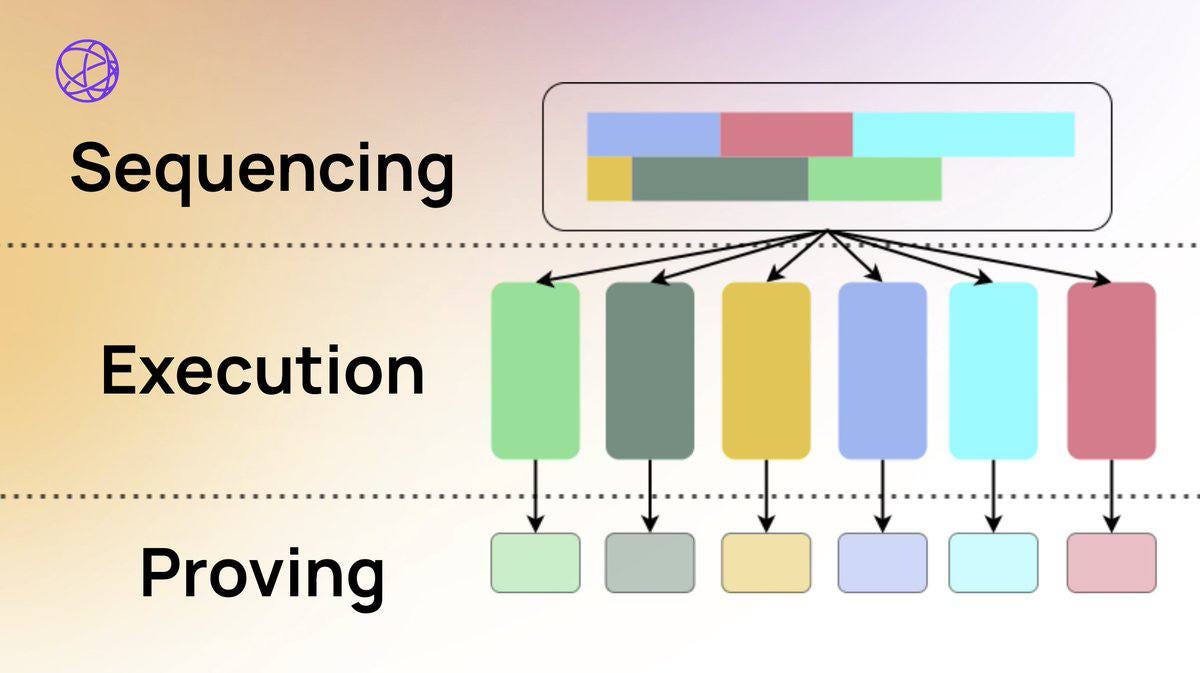
3. The sequencer in a rollup gets transactions from the mempool, determines their execution order, and provides the instructions to the VM, publishing checkpoints periodically to the rollup contract on ETH
4. For zero-knowledge Rollups, a prover generates proof for VM state transition, which is then submitted as a new state root to rollup contract on ETH
The image below is a representation of a Centralized Sequencer
5. The rollup then checks to confirm the validity of the proof; if valid, state transitions will be registered
Centralized Sequencer
We could use the L1 as a sequencer but it has its many downsides
- low transactions and data throughput
- L1 computational bottlenecks will be alleviated, and slower transactions confirmation
Users will experience the issue modularity is trying to solve— L1 congestion which has led to a high gas and low throughput. However, Rollups today choose to assume control and try to figure out how to decentralize their own sequencers all on their own, which they fail to do. We’ve seen the case with the L1 sequencer option too and its disadvantages. Rollups should, therefore, opt into a Shared Sequencer design
Messiah ie — Decentralized Shared Sequencer
These are the many benefits:
- Sequencer Simplification: It seems it’s hard for rollups to decentralize their sequencer
Hence, this option is best, opt for a DSS and scale better. Also, it means you being Modular enough; as it stands and left to me we are in the Modular age of web3.
- Shared Security and Decentralization: Rather than a single sequencer committee, Rollups should aim to opt into a shared sequencer committee because it comes with benefits like a well-protected layer of high-value staked efficient sequencer nodes, and this yields decentralization. Rather than a few committees of sequencer nodes with low-value stake to protect the layer. And this doesn’t yield Censorship resistance
Censorship Resistance. What’s that?
Sequencers are used to batch transactions and post to the L1 contract. So a user might want to include his/her transactions in a contract by bribing $$ thanks to MEV. Then Sequencer sees it, accepts, and promises to add transactions to L1. Sequencer then posts these transactions to L1
The bridging of funds from L1 to L2 vice versa is via a mint and burn process. Also, users bridging funds from L1 to L2 is done by the L1 telling the L2 that it can mint funds on L2 backed by the locked asset on L1. If the user wants to get funds back to L1 from L2, it’s done through a burn process. The user can burn it on L2 and tell L1 to accept funds.
However, in unforeseen circumstances, the L1 is unaware of whatever issue might be going on in L2. This is where not being CR comes in, the L2 might not like the user for a reason; either he’s a known scammer, etc, or used a banned L1 (e.g. the Tornado situation). The user herein has the right to force the inclusion of a transaction in the L2 or force withdrawal from it, which is expensive for an average user.
Hence, Rollups should increase their CR assurances as L1. L1 eth in this instance has a lot of staked value to protect the network with wide node sequencer consensus.But Rollup (L2) can’t use L1 cos of the hindrances we explained earlier. Now, Decentralized Shared Sequencer comes as the Messiah to enable CR effectiveness
With shared sequencer value stacked node. Users shouldn’t be scared of CR
- Cross-Chain Atomicity:
“Atomicity 🤔, Chemistry! Nah, chill”
Atomicity derives from the word atomic, which means it has no substates, ie it’s either it happens or doesn’t. Cross Chain Atomicity here, denotes transactions that occur between different rollups.
User- Potter would execute a transactions differently from User- Wesley. Potter’s transactions might get sequenced before Wesley’s. This will give Wesley an opportunity to abort the transactions. This causes unfairness which is mitigated by SS. Leaving Potter and Wesley can submit their transactions together.
Teams building Decentralized Shared Sequencer
Espresso Systems @EspressoSys
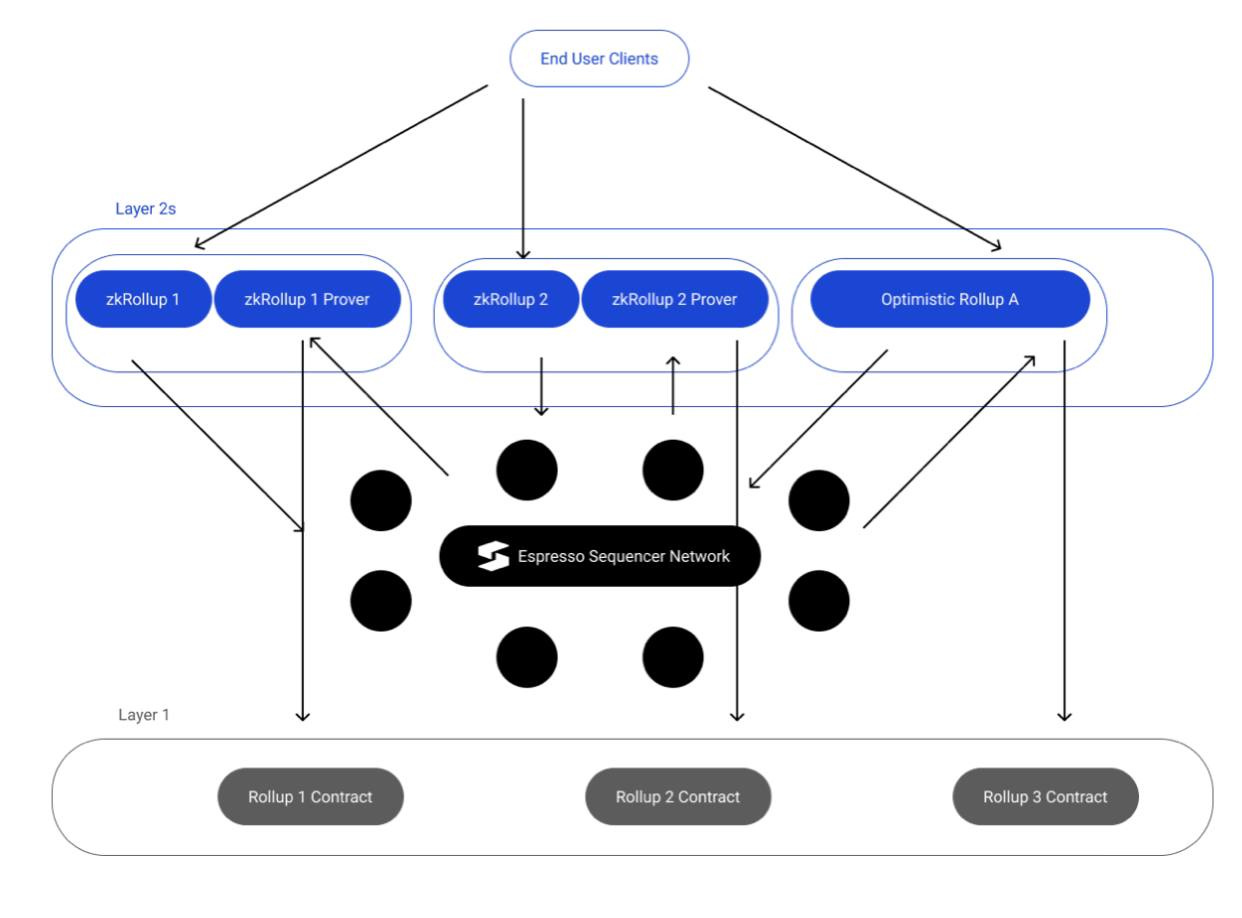
DA- EspressoDA
Security layer - Eigenlayer @eigenlayer
Astria- @AstriaOrg
DA - @CelestiaOrg
Also, radius for tech advancements in this
Will write in detail about their tech in future articles
Sources
https://hackmd.io/@EspressoSystems/SharedSequencing?utm_source=preview-mode&utm_medium=rec